



.jpg)



当前位置:首页»案例
- 如何创建及谐调支持多核的LabVIEW x86客户DLL
-
企业: 美国国家仪器(NI)有限公司 日期: 2009-05-20 领域: 运动控制 点击数: 654 The Challenge:
对NI LabVIEW软件自动生成的外部代码进行最优化,在x86构架下获得最大性能,进而测量目标系统中DLL性能。The Solution:
在不修改源代码的条件下,通过Intel C++ 编译器在单核PC上实现2.5 倍提速,通过编译器中的各类最优化选项在双核PC 上实现超过4.5 倍提速。"VTune能够监测许多不同种类的构架事件。VTune调谐助手能够给出如何更好使用这些事件的建议。"
本应用包括了两个组件——用于计算Pi 值的DLL、调用DLL 库函数的LabVIEW 应用,可将结果显示在图形用户界面中。为计算Pi 值,我们采用了近似综合技术,需要在单个循环中完成数百万次浮点计算。选择该范例是因为它是CPU 密集型的,并且是可优化的应用。如下所示为外部代码的主循环结构,CPU的主要计算量是处理CalcSum 函数。
for(i=0; i<num_steps; i++)
{
sum = CalcSum(i, sum, step);
}我们的目标是通过编译器中的优化选项以最快速度完成上述计算。
应用中有4 个函数,均包含于独立源文件中。我们采用不同优化开关来编译每个源文件。如图1 所示。
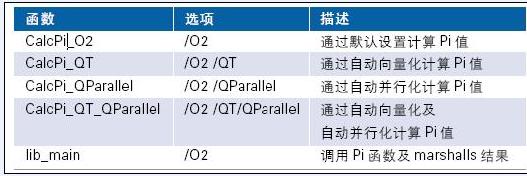
表1.应用中的函数
“即插即用”的Intel C++ 编译器
我们采用即插即用的Intel C++ 来代替Microsoft 编译器,它可以轻松地集成到现有Microsoft Visual Studio DLL 工程中。更多关于Intel 编译器,请访问intel.com/software。默认设置
测量首先以/O2选项创建应用,许多优化都是在这个层面上进行的。本文在此不讨论其细节问题。表2显示了/O2选项集成的各个优化设置。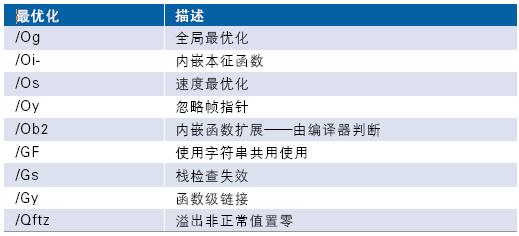
表2./O2 选项中集成的最优化列表
自动向量化
自动向量化得益于新一代CPU 中集成的复杂指令集。多数现代CPU构架可扩展支持数据操作及多数据计算。扩展包括支持以单一指令实现多重计算(单指令多数据流,或称SIMD)。Intel 编译器能够分析代码,并通过SIMD 指令显著提高代码的效率。本范例中,编译器通过\QT 选项生成适合Core 2 构架的代码,编译器报告以下创建时间信息:
注释:循环未作向量化处理
反汇编生成代码后可看到编译器插入了SIMD扩展指令集(SSE)。该指令集的使用直接提升了应用的运行性能,代码运行速度提高了2倍。
这类优化可应用于目前大多数CPU 上,这里我们在Core 2 处理器上运行,当然您也可以在单核或早期CPU 上应用。
自动并行化
因为采用多核PC,我们会更感兴趣如何通过\QParallel 选项,让代码在两核上同时运行,以获得进一步提速。该选项在编译目标中插入了库调用。库调用提供了运行时所需的控制,使应用中的组件得以并行。在首次运行中,编译器并未显著提高运行性能。通过开启编译器的报告功能,可以看到它并未进行优化。
注释:循环未作并行化处理,循环无需并行化
Intel编译器要对一段代码进行自动并行化时,首先决定是否有值得进行并行化的代码部分。在我们的代码中由一个主循环完成所有工作。编译器不能确定循环的重复次数,循环计数值只有在运行时得到。于是编译器采取谨慎选择,不对循环进行并行化处理。
我们可以通过在命令行输入/Qpar-threshold:n 来进行试探优化,这里n 是介于0(总是并行处理)到100(不进行并行处理)的数,这个值决定了试探优化的程度。
输入/Qpar-threshold:0 后,编译器对代码并行化,并输出报告:
注释:循环已作自动并行化处理
使用该优化后,程序的运行速度比默认设置下提高了近2 倍。
其它优化选项
本范例中,我们关注自动向量化及自动并行化。Intel C++ 编译器利用一系列其它优化技术,包括高层优化、交叉过程优化、配置向导优化、速度优化、代码大小优化、快速浮点处理等。Intel 编译器同时支持OpenMP 这个基于pragma 的标准,用于实现应用代码的并行化。
测量性能
本范例中我们采用Win32 API 的定时函数,并将定时计算嵌入外部代码。计算时间在LabVIEW 应用GUI 中显示。作为备选,我们还可采用LabVIEW的定时工具,或采用外部工具,如Intel VTune 性能分析器。
VTune能够监测许多不同种类的构架事件。VTune调谐助手能够给出如何更好使用这些事件的建议。
结论
不同开关的优化结果在表3 中列出。我们在双核PC 上运行,并通过默认优化(/O2)作为基准来计算提速。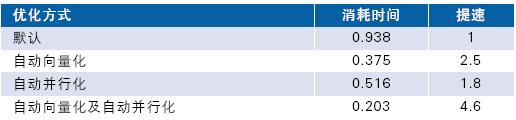
表3.不同优化方式下的速度提高
在应用自动向量化时可达到2.5倍速,该优化专用于非多核处理器,可用于目前多数CPU。
在应用自动并行化后可实现接近2 倍的提速。结合两种优化更可达到4.6 倍。
以上结果是在不修改源代码的前提下实现的。尽管我们选择了模拟应用(计算Pi值),但这类优化技术能够用于各类实际应用。从Intel编译器用户反馈中了解到,使用这些优化方式可显著提高代码执行速度。
- 下载排行更多»
-
- 1Power Panel宣传样本
- 2公司形象手册
- 3工业PC宣传样本
- 4集成自动化宣传样本
- 5驱动器产品概览样本
- 6贝加莱CNC技术
- 7电机与减速器产品概览
- 8变频器样本
- 9移动车辆及工程机械自动化
- 10Automotion 2013-03
- 11印刷行业专刊(2013)
- 12培训模块之 TM213-自动化操作系统(Runti..
- 13培训模块之 TM210-Automation Studio 3.0..
- 14操作面板和工业PC选型手册
- 15电机和减速器选型手册
- 16APROL DCS宣传样本
- 17APROL EnMon宣传样本
- 182013年菲尼克斯电气德国汉诺威展会精彩回顾
- 192013年菲尼克斯电气德国汉诺威展会报道-4..
- 202013年菲尼克斯电气德国汉诺威展会报道-4..
- 212013年菲尼克斯电气德国汉诺威展会报道-4..
- 222013年菲尼克斯电气德国汉诺威展会报道-4..
- 在线反馈
| 1.我有以下需求: | |
|
|
|
| 2.详细的需求: | |
| * | |
| 姓名: | * |
| 单位: | |
| 电话: | * |
| 邮件: | * |

电话:010-62669087 控制网版权所有未经许可不得转载
地址:北京市海淀区上地十街辉煌国际5号楼1416室(100085)
版权所有 控制网 京ICP备14036844-2号 北京市公安局海淀分局备案号:11010802023656号
北京市公安局海淀分局备案号:11010802023656号
地址:北京市海淀区上地十街辉煌国际5号楼1416室(100085)
版权所有 控制网 京ICP备14036844-2号